Using your component in a kubeflow pipeline
You can complie and run a kubeflow pipeline using your component with this walkthrough.
Test Environment
- Provisioning machine - Ubuntu 18.04
- Node machines - Ubuntu 20.04
- deepops - 22.08
- kubernetes - 1.23.7
- kubeflow - 1.6.1
Walkthrough
0. Prerequisition
- Kubeflow installed on Kubernetes
- Python packages(libraries) installed
- requests
- kubernetes
- kfp
1. Using your component in a pipeline
In python script, you can use the Kubeflow Pipelines SDK to load your component using methods such as the following:
- kfp.components.load_component_from_file: Use this method to load your component from a
component.yamlpath. - kfp.components.load_component_from_url: Use this method to load a
component.yamlfrom a URL. - kfp.components.load_component_from_text: Use this method to load your component specification YAML from a string.
The following example demonstrates how to load your component specification and run it.
import os
import requests
import kfp
from kfp import components, dsl
download_dataset_op = components.load_component_from_file('./PATH/TO/component.yaml')
create_yolotxt_op= components.load_component_from_file('./PATH/TO/component.yaml')
train_yolov5_op = components.load_component_from_file('./PATH/TO/component.yaml')
# Kubeflow account
KF_HOST = "YOUR_KUBEFLOW_SERVER_HOST"
KF_USERNAME = "YOUR_KUBEFLOW_USERNAME"
KF_PASSWORD = "YOUR_KUBEFLOW_PASSWORD"
KF_NAMESPACE = "YOUR_KUBEFLOW_NAMESPACE"
@dsl.pipeline()
def my_pipeline(
# NAS account & data path
nas_host: str = 'YOUR_NAS_HOST',
nas_username: str = 'YOUR_NAS_USERNAME',
nas_pwd: str = 'YOUR_NAS_PASSWORD',
nas_data_dir: str = '/PATH/TO/RAW/DATASET',
nas_yolotxt_dir: str = '/PATH/TO/TRAINING/DATASET',
nas_model_dir: str = '/PATH/TO/SAVE/MODEL',
# WANDB account
WANDB_API_KEY: str ='YOUR_KEY_STRING',
# Training settings
NPROC: int = 1, # Number of GPU used per machine
M_PORT: int = 1,
IMG_SIZE: int = 640,
BATCH_SIZE: int = 32,
EPOCH_NUM: int = 600,
WEIGHT_PATH: str = "yolov5s.pt",
DEVICE_IDS: str = "0",
DATASET_FROM: str = "NAS",
):
# Download Pascal VOC dataset
dataset = download_dataset_op(
sftp_host=nas_host,
sftp_username=nas_username,
sftp_pwd=nas_pwd,
sftp_dir=nas_data_dir,
)
# Convert raw data to yolo txt
training_data = create_yolotxt_op(
data_dir=dataset.output,
output_path='datasets',
sftp_host=nas_host,
sftp_username=nas_username,
sftp_pwd=nas_pwd,
sftp_dir=nas_yolotxt_dir
).after(dataset)
# Training YOLOv5
checkpoint = train_yolov5_op(
wandb_key=WANDB_API_KEY,
nproc_per_node=NPROC,
master_port=M_PORT,
image_size=IMG_SIZE,
batch=BATCH_SIZE,
epochs=EPOCH_NUM,
data=os.path.join(os.path.basename(str(nas_yolotxt_dir)), 'petfins_v3.yaml'),
weights=WEIGHT_PATH,
device=DEVICE_IDS,
data_from=DATASET_FROM,
sftp_host=nas_host,
sftp_username=nas_username,
sftp_pwd=nas_pwd,
sftp_data_dir=nas_yolotxt_dir,
sftp_model_dir=nas_model_dir
).after(training_data)
# Create pipeline run on kubeflow
session = requests.Session()
response = session.get(KF_HOST)
headers = {
"Content-Type": "application/x-www-form-urlencoded",
}
data = {"login": KF_USERNAME, "password": KF_PASSWORD}
res = session.post(response.url, headers=headers, data=data)
session_cookie = session.cookies.get_dict()["authservice_session"]
client = kfp.Client(
host=f"{KF_HOST}/pipeline",
cookies=f"authservice_session={session_cookie}",
namespace=KF_NAMESPACE,
).create_run_from_pipeline_func(my_pipeline, arguments={}, namespace=KF_NAMESPACE)
Input and output names should convert to Pythonic names (spaces and symbols are replaced with underscores and letters are converted to lowercase). For example, an input named Input 1 is converted to input_1.
kfp.Client.create_run_from_pipeline_func will create only a pipeline run without pipeline. If you want to create pipeline itself, you can use the function kfp.compiler.Compiler().compile for getting your pipeline YAML.
client = compiler.Compiler().compile(my_pipeline, "MyPipeline.yaml")
Then, you can upload the YAML file to kubeflow for creating pipeline through your kubeflow dashboard.
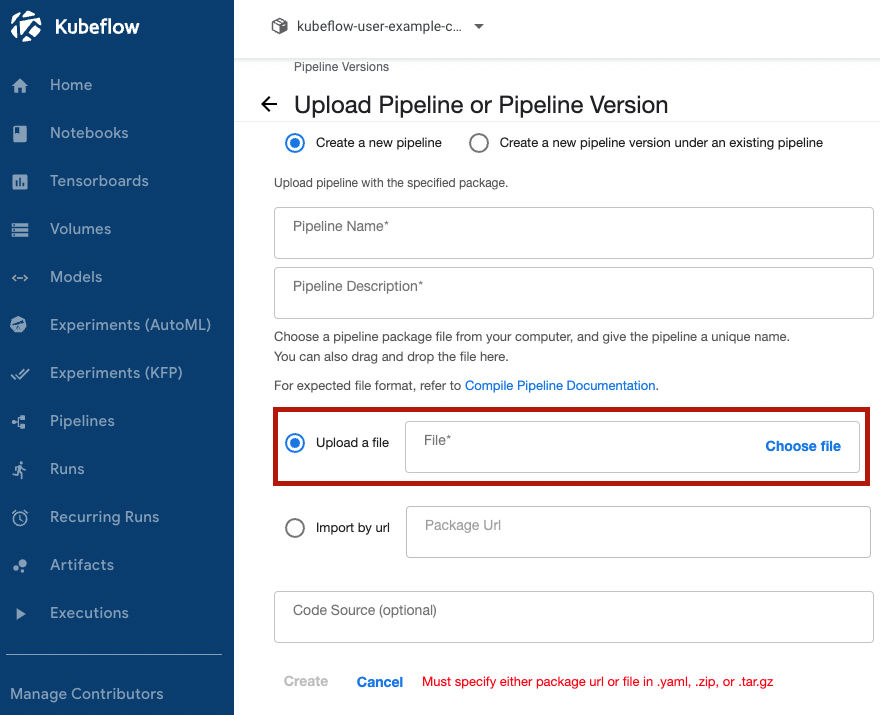
99. FAQ
- ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm)
from kfp import dsl
import kubernetes as k8s
@dsl.pipeline()
def my_pipeline():
volume = dsl.PipelineVolume(volume=k8s.client.V1Volume(
name="shm",
empty_dir=k8s.client.V1EmptyDirVolumeSource(medium='Memory')))
checkpoint = train_yolov5_op(
# inputs...
)
checkpoint.add_pvolumes({'/dev/shm': volume})
- Do not want to use cache for running my components.
checkpoint.execution_options.caching_strategy.max_cache_staleness = "P0D"
Leave a comment